summit 2021
The State & Future of eBPF – Thomas Graf

eBPF 解决的几个问题:
- 内核开发下层应用需要的特性,需要很长的时间适配
- 从内核开发完成,到发行版可以使用此内核版本还有更久的时间
projects
- katrans
- bcc
- cilium
by google cloud. Ebpf networking security, observablity - falco
- faatran
- bptfrace
sdk
- python
- go
- c++
- rust
Getting Started with BPF observability
Brendan Gregg. Netflix 大佬
- 观点:ebpf 更新很快,很多文档已经过时
- BPF是一个技术名,不再是一个简写
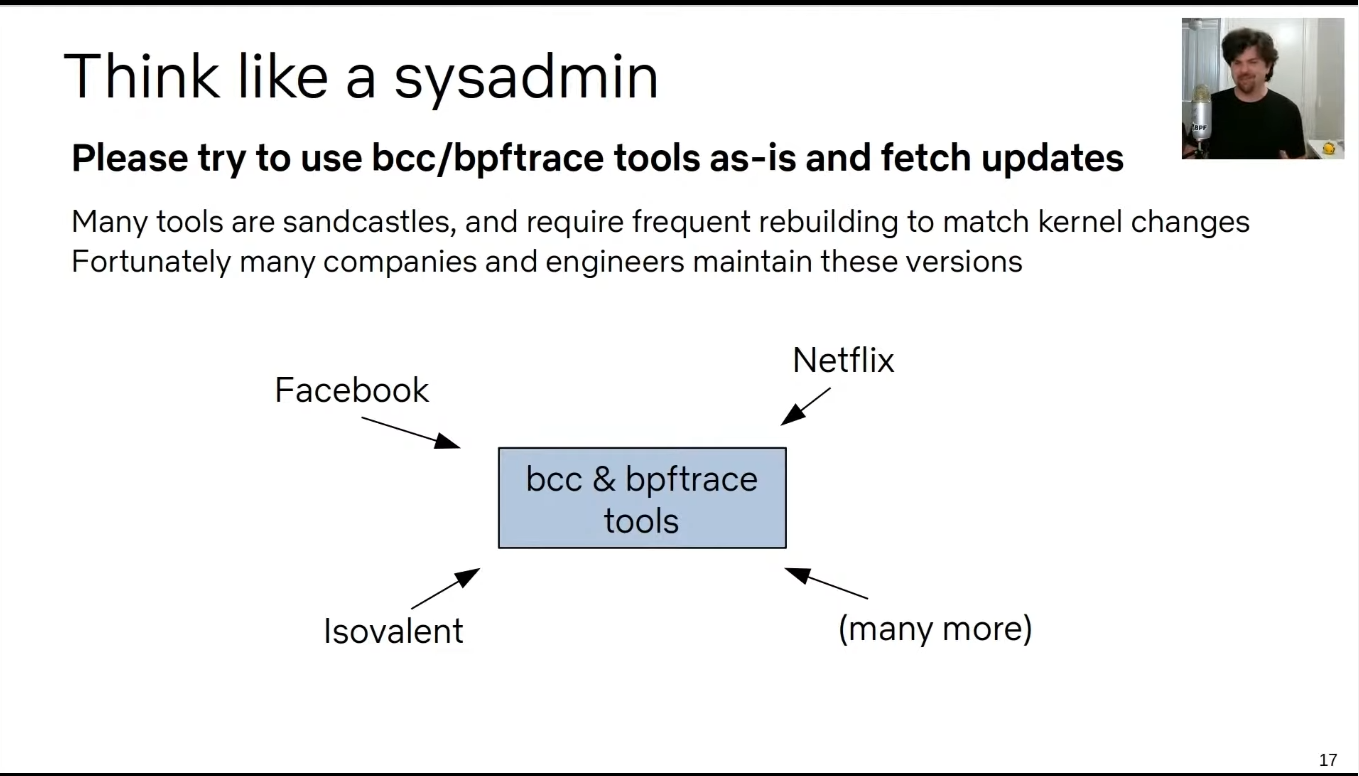
Think like a sysadmin

- bcc & bpftrace
- iostat vs biosnoop
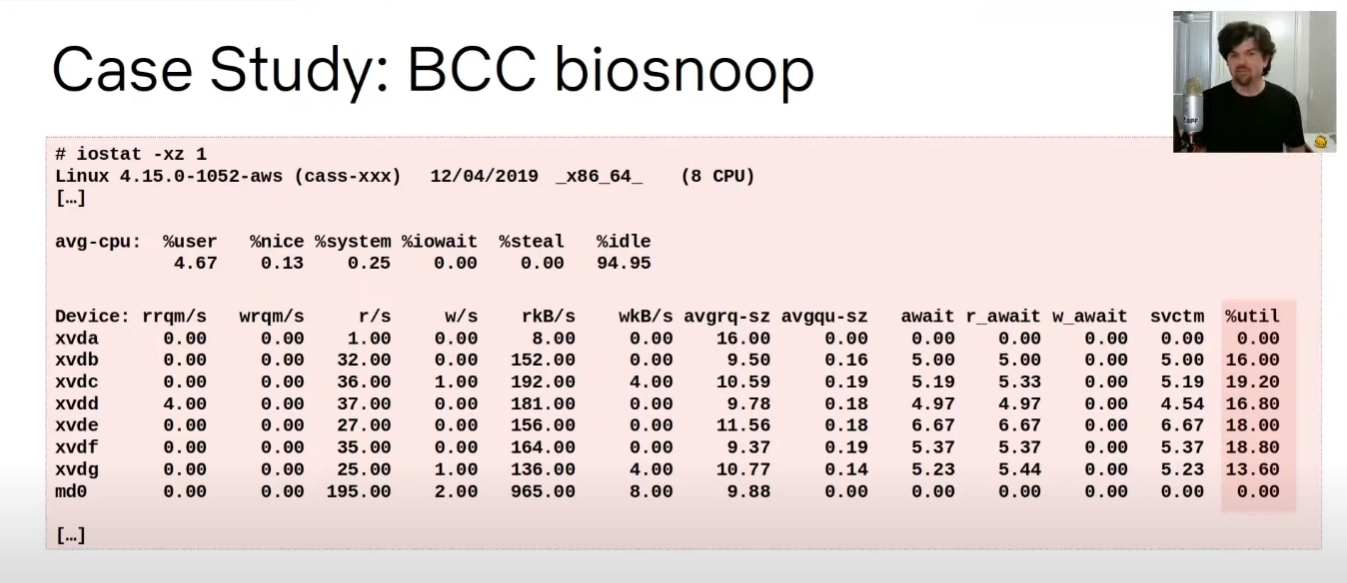
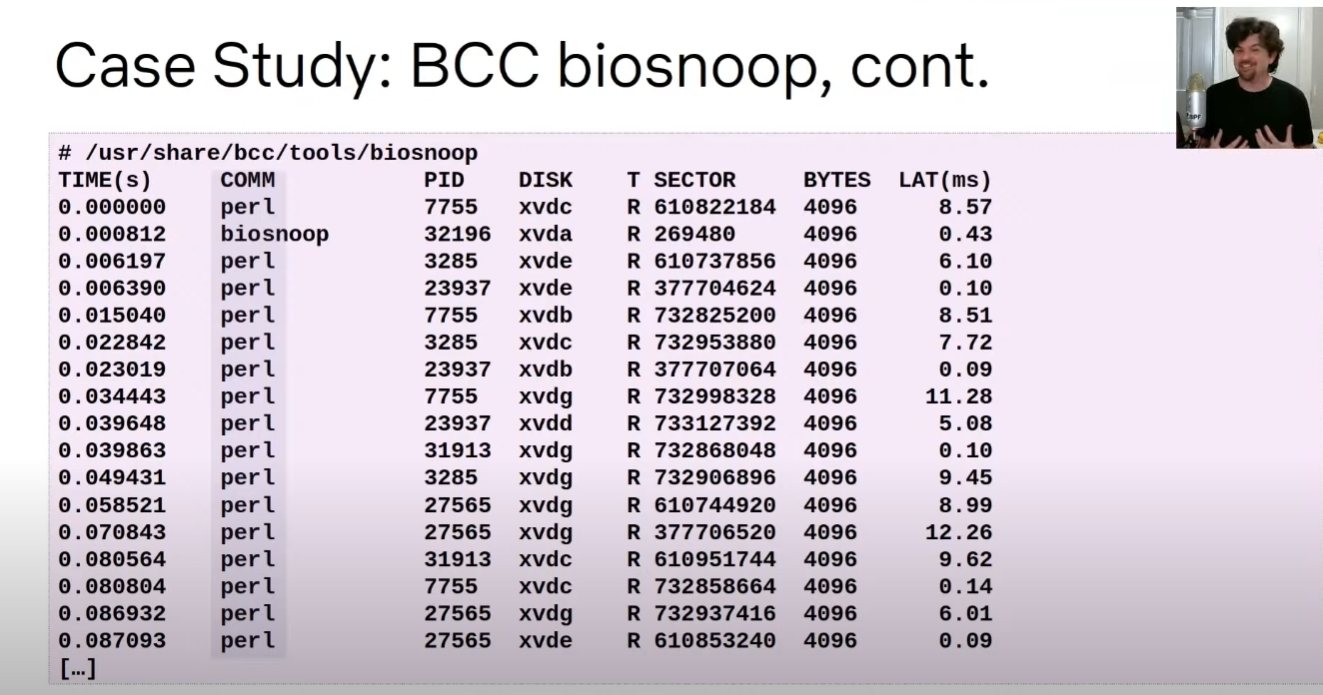
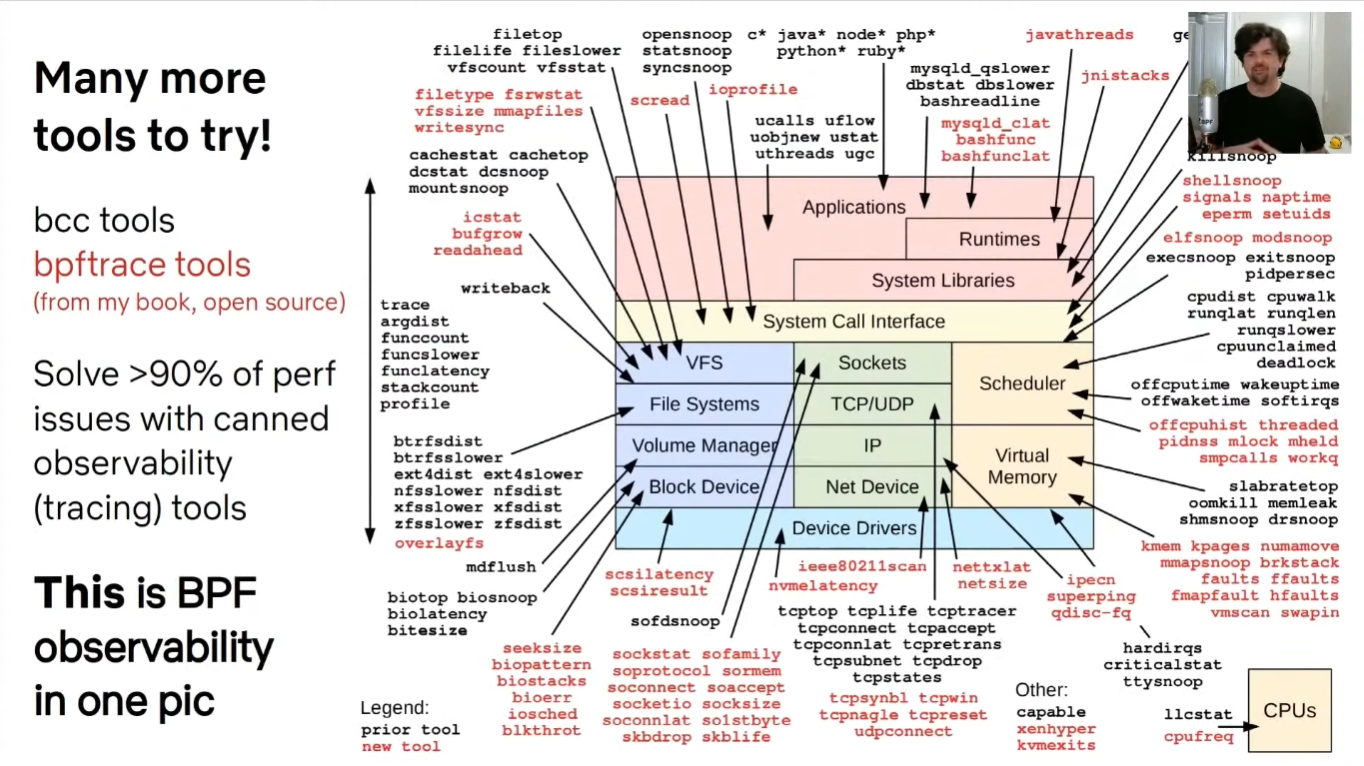
原图:
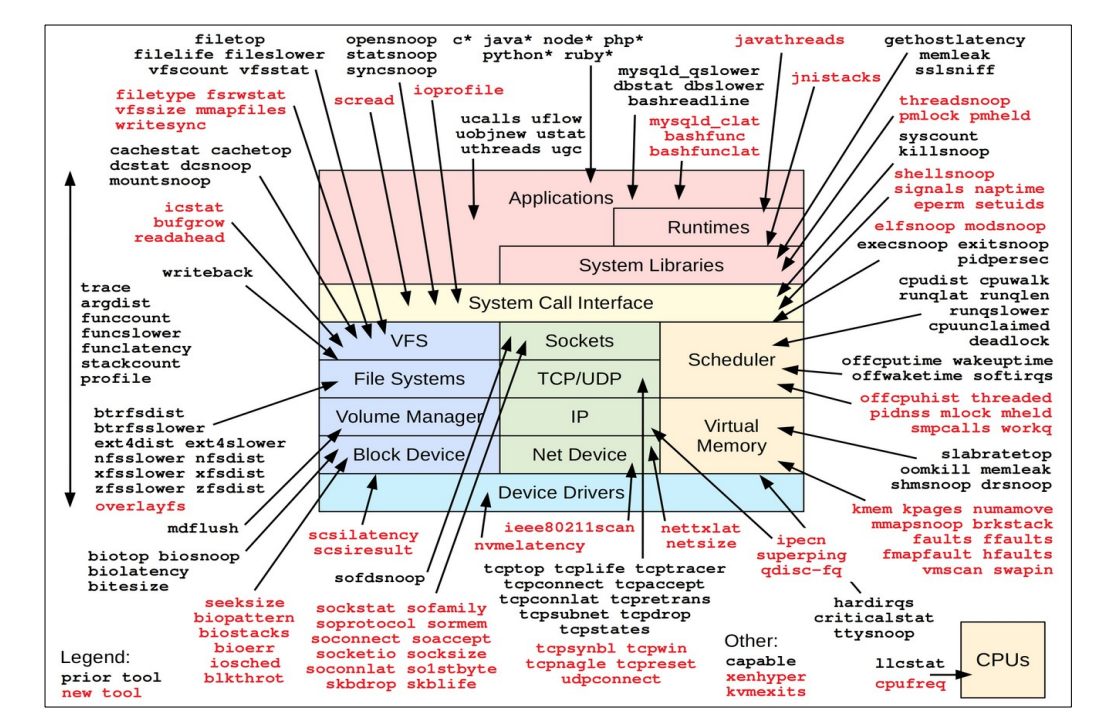
- 使用封装好的工具解决90%的问题
- 未来:白屏化

- Netflix 的一种(过时的)实现
master – agent 模式,似乎不能看到历史的数据

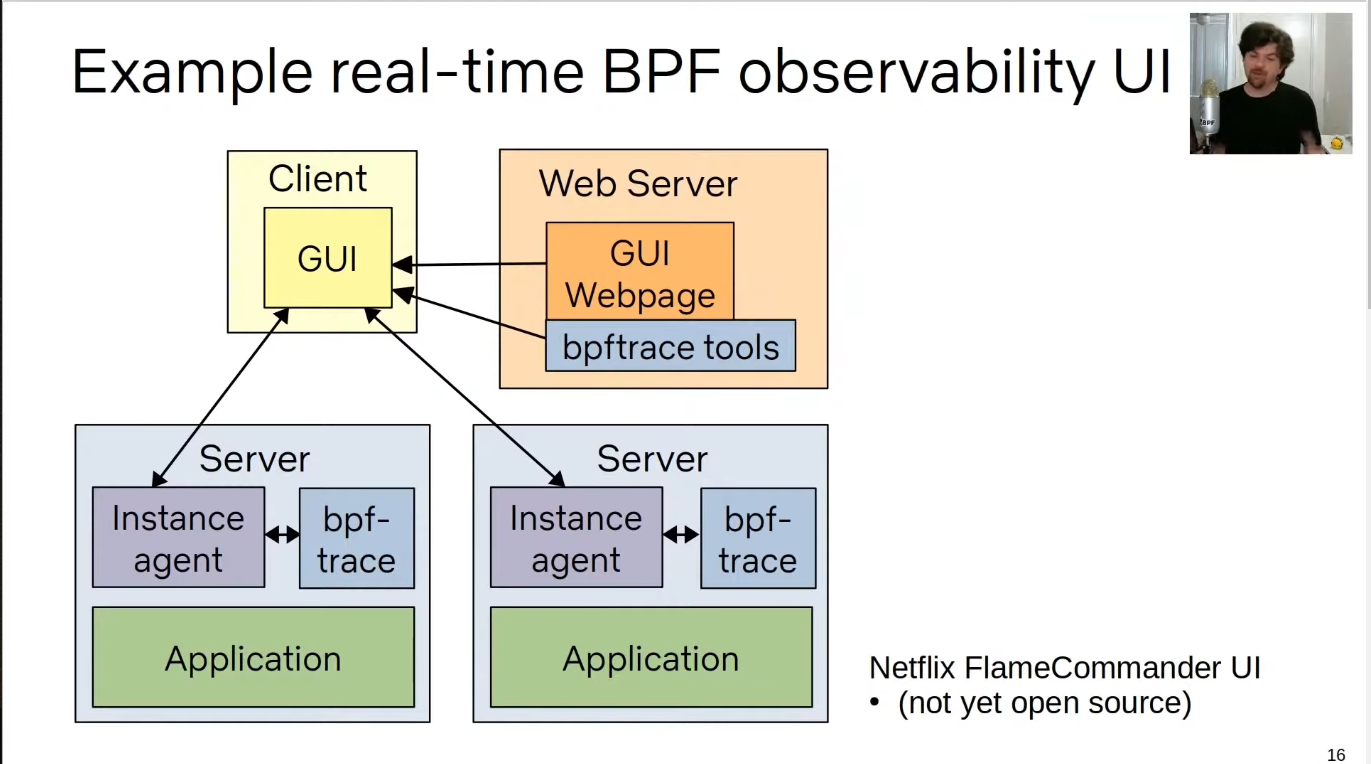
- 建议使用最新的 bcc 和 bpftrace。不要承担适配内核版本的维护工作
Not like a programmer
- 适配的前端:

- CONFIG_DEBUG_INFO_BTF=y
BPF Future: Event based appliocations
eBPF in Microservices Observability
By Janna Dogen (AWS)
hooks into…
- kernel & user funcs
- sys calls
- network events
- kernel tracepoints
challenges in microservies
- We don’t just monitor VMs or processes. We monitor critical paths.
- Context matters. Downstream stack don’t have context.
- We initially debug RPCs. We debug functions or syscalls secondarily.
- Too much data. Need runtime controls to modify the collection.
- M:N Problem ??
Continuous Profiling in Production with eBPF
Omid Azizi, Pete Stevenson (Pixie Labs, New Relic)
- 91Hz 下 0.1% 性能损耗,很理想
https://blog.px.dev/cpu-profiling-3/

这个像是来推销产品的 pixie
eBPF Capture the Flag #1 (CTF)
By. Tabitha Sable (Datadog)
day 1 summit 后面的内容要么泛善可陈,要么关注于网络或者安全内容
BPF Library Ecosystem Overview in Go, Rust, Python, and C
Kyle Quest (Slim.AI)
Libraries
- C: bcc, libbpf
-
- bcc most mature 👍
- libbpf – official low-level lib by ebpf kernel maintainers 👍
- Go: iovisor/gobpf, cilium/ebpf, dropbox/goebpf, libbpfgo
-
- iovisor/gobpf official 👍 (虽然如此,版本更新的频率也不高)
- cilium/ebpf not a wrapper, pure go lib 👀 focus on networking, but tracing/profiling is now supported
- dropbpx/goebpf not a wrapper pure go 👀 focus on networking
- libbpfgo – libbpf wrapper in go
- Python: bcc, pyebpf
-
- bcc – official bcc wrapper 👍 python 3
- pyebpf – bpc wrapper with extras 👎 dated, python 2
- Rust: libbpf-rs, redbpf, aya
-
- libbpf-rs – lightweight libbpf wrapper. almost official
- redbpf – libbpf wrapper
- aya – pure rust lib. early ( 作者就是在下个talk)
最后一次发布在 6月6日
- Other: Lua (bcc), Node.js (bpf, bpfcc), Ruby (rbbcc)
-
- lua – official 👎
- node_bpf 👎 experimental
- node_bpfcc 👎
Why Rust is Increasing Becoming a Great Option for Writing eBPF Programs
Alessandro Decina (Deepfence)
感觉现在还不是上车Rust的最佳时机
- XDP-FW?
A Beginner’s Guide to eBPF Programming
2020 年 Liz Rice 的 talk,ABC 级别教程,值得看一看
- ioctl
- kprobe
Liz Rice
- ebpf let you run custom code in the kernel
- 调用 ebpf的过程也是一个syscall——bpf
- 使用 clang 编译为 ebpf 字节码(被限制的c语言:不能用循环、浮点数、函数参数传递结构体)
- bpftrace
- bcc
-
- helper functions ?
-
-
- bpf_get_current_uid_gid
-
-
- map
-
-
- hash table
-
eBPF 数据结构
ref: https://www.cnblogs.com/charlieroro/p/13403672.html
eBPF使用的主要的数据结构是eBPF map,这是一个通用的数据结构,用于在内核或内核和用户空间传递数据。其名称”map”也意味着数据的存储和检索需要用到key。
|
NAME |
DESC |
|
BPF_MAP_TYPE_HASH |
a hash table |
|
BPF_MAP_TYPE_ARRAY |
an array map, optimized for fast lookup speeds, often used for counters |
|
BPF_MAP_TYPE_PROG_ARRAY |
an array of file descriptors corresponding to eBPF programs; used to implement jump tables and sub-programs to handle specific packet protocols |
|
BPF_MAP_TYPE_PERCPU_ARRAY |
a per-CPU array, used to implement histograms of latency |
|
BPF_MAP_TYPE_PERF_EVENT_ARRAY |
stores pointers to struct perf_event, used to read and store perf event counters |
|
BPF_MAP_TYPE_CGROUP_ARRAY |
stores pointers to control groups |
|
BPF_MAP_TYPE_PERCPU_HASH |
a per-CPU hash table |
|
BPF_MAP_TYPE_LRU_HASH |
a hash table that only retains the most recently used items |
|
BPF_MAP_TYPE_LRU_PERCPU_HASH |
a per-CPU hash table that only retains the most recently used items |
|
BPF_MAP_TYPE_LPM_TRIE |
a longest-prefix match trie, good for matching IP addresses to a range |
|
BPF_MAP_TYPE_STACK_TRACE |
stores stack traces |
|
BPF_MAP_TYPE_ARRAY_OF_MAPS |
a map-in-map data structure |
|
BPF_MAP_TYPE_HASH_OF_MAPS |
a map-in-map data structure |
|
BPF_MAP_TYPE_DEVICE_MAP |
for storing and looking up network device references |
|
BPF_MAP_TYPE_SOCKET_MAP |
stores and looks up sockets and allows socket redirection with BPF helper functions |
使用bpf()系统调用创建和管理map。当成功创建一个map后,会返回与该map关联的文件描述符。关闭相应的文件描述符的同时会销毁map。每个map定义了4个值:类型,元素最大数目,数值的字节大小,以及key的字节大小。eBPF提供了不同的map类型,不同类型的map提供了不同的特性。
所有的map都可以通过eBPF或在用户空间的程序中使用 bpf_map_lookup_elem() 和bpf_map_update_elem()函数进行访问。某些map类型,如socket map,会使用其他执行特殊任务的eBPF辅助函数。
A Load Balancer from Scratch
Liz Rice (Isovalent)
网络相关
全面介绍eBPF-概念
https://www.cnblogs.com/charlieroro/p/13403672.html by charlieroro
一篇不错的博客,发布于 2020-08-09 20:52,部分内容可能需要更新。
bpf 系统调用
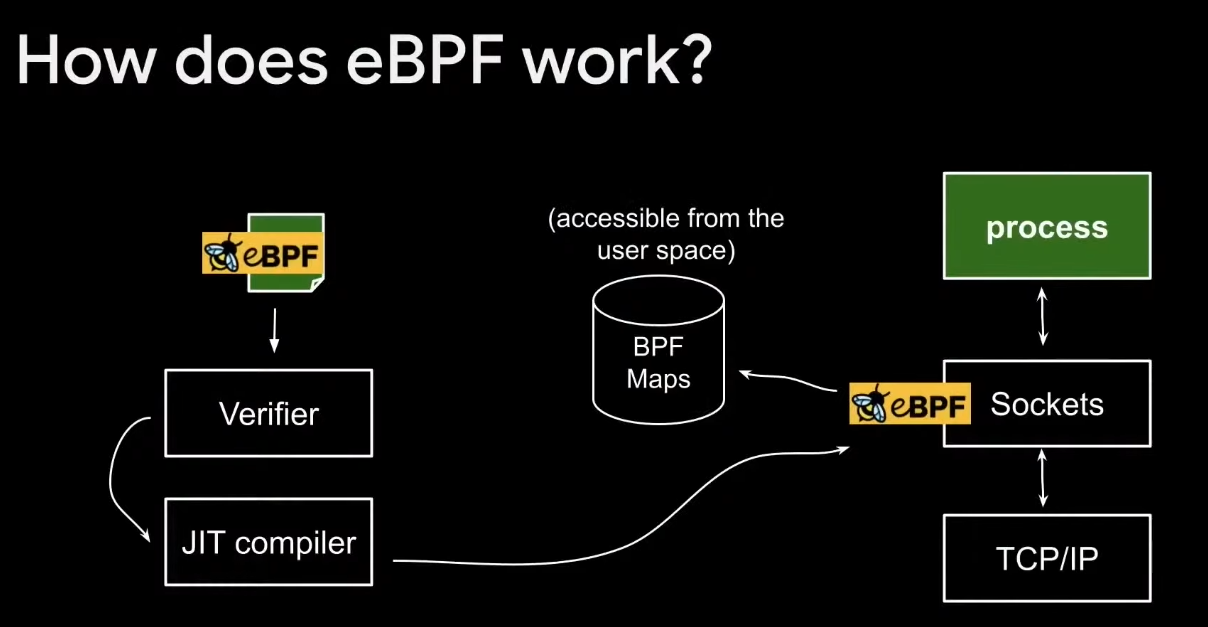
ebpf 虚拟机运行在内核。用户态的函数调用内核的函数是syscall,ebpf也不例外。

eBPF 程序类型
使用BPF_PROG_LOAD加载的程序类型确定了四件事:附加的程序的位置,验证器允许调用的内核辅助函数,是否可以直接访问网络数据报文,以及传递给程序的第一个参数对象的类型。实际上,程序类型本质上定义了一个API。创建新的程序类型甚至纯粹是为了区分不同的可调用函数列表(例如,BPF_PROG_TYPE_CGROUP_SKB 和BPF_PROG_TYPE_SOCKET_FILTER)。
当前内核支持的eBPF程序类型为:(删掉了所有网络相关的,是否过时?)
- BPF_PROG_TYPE_SOCKET_FILTER: a network packet filter
- BPF_PROG_TYPE_KPROBE: determine whether a kprobe should fire or not
- BPF_PROG_TYPE_SCHED_CLS: a network traffic-control classifier
- BPF_PROG_TYPE_SCHED_ACT: a network traffic-control action
- BPF_PROG_TYPE_TRACEPOINT: determine whether a tracepoint should fire or not
- BPF_PROG_TYPE_XDP: a network packet filter run from the device-driver receive path
- BPF_PROG_TYPE_PERF_EVENT: determine whether a perf event handler should fire or not
- BPF_PROG_TYPE_CGROUP_SKB: a network packet filter for control groups
- BPF_PROG_TYPE_CGROUP_SOCK: a network packet filter for control groups that is allowed to modify socket options
- BPF_PROG_TYPE_LWT_*: a network packet filter for lightweight tunnels
- BPF_PROG_TYPE_SOCK_OPS: a program for setting socket parameters
- BPF_PROG_TYPE_SK_SKB: a network packet filter for forwarding packets between sockets
- BPF_PROG_CGROUP_DEVICE: determine if a device operation should be permitted or not
随着新程序类型的增加,内核开发人员也会发现需要添加新的数据结构。
- CONFIG_BPF_JIT_ALWAYS_ON 参数
eBPF 辅助函数
https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
官方文档给出了现有的eBPF辅助函数。更多的实例可以参见内核源码的samples/bpf/和tools/testing/selftests/bpf/目录。
在官方帮助文档中有如下补充:
由于在编写帮助文档的同时,也同时在进行eBPF开发,因此新引入的eBPF程序或map类型可能没有及时添加到帮助文档中,可以在内核源码树中找到最准确的描述:
include/uapi/linux/bpf.h:主要的BPF头文件。包含完整的辅助函数列表,以及对辅助函数使用的标记,结构体和常量的描述
net/core/filter.c:包含大部分与网络有关的辅助函数,以及使用的程序类型列表
kernel/trace/bpf_trace.c:包含大部分与程序跟踪有关的辅助函数
kernel/bpf/verifier.c:包含特定辅助函数使用的用于校验eBPF map有效性的函数
kernel/bpf/:该目录中的文件包含了其他辅助函数(如cgroups,sockmaps等)
如何编写eBPF程序
历史上,需要使用内核的bpf_asm汇编器将eBPF程序转换为BPF字节码。幸运的是,LLVM Clang编译器支持将C语言编写的eBPF后端编译为字节码。bpf()系统调用和BPF_PROG_LOAD命令可以直接加载包含这些字节码的对象文件。
可以使用C编写eBPF程序,并使用Clang的 -march=bpf参数进行编译。在内核的samples/bpf/ 目录下有很多eBPF程序的例子。大多数文件名中都有一个_kern.c后缀。Clang编译出的目标文件(eBPF字节码)需要由一个本机运行的程序进行加载(通常为使用_user.c开头的文件)。为了简化eBPF程序的编写,内核提供了libbpf库,可以使用辅助函数来加载,创建和管理eBPF对象。例如,一个eBPF程序和使用libbpf的用户程序的大体流程为:
- 在用户程序中读取eBPF字节流,并将其传递给bpf_load_program()。
- 当在内核中运行eBPF程序时,将会调用bpf_map_lookup_elem()在一个map中查找元素,并保存一个新的值。
- 用户程序会调用 bpf_map_lookup_elem() 读取由eBPF程序保存的内核数据。
然而,大部分的实例代码都有一个主要的缺点:需要在内核源码树中编译自己的eBPF程序。幸运的是,BCC项目解决了这类问题。它包含了一个完整的工具链来编写并加载eBPF程序,而不需要链接到内核源码树。
一般不会直接编写ebpf程序,需要配合bcc或者libbpf来写。
BCC(可观测性)
https://www.cnblogs.com/charlieroro/p/13265252.html by charlieroro on 2020-07-08
部分内容可能需要更新
bcc-tools
apt install bpfcc-tools cd /usr/sbin ls | grep bpfcc # centos yum install bcc-tools cd /usr/share/bcc/tools ls
可以得到
argdist-bpfcc bashreadline-bpfcc bindsnoop-bpfcc biolatency-bpfcc biolatpcts-bpfcc biosnoop-bpfcc biotop-bpfcc bitesize-bpfcc bpflist-bpfcc btrfsdist-bpfcc btrfsslower-bpfcc cachestat-bpfcc cachetop-bpfcc capable-bpfcc cobjnew-bpfcc compactsnoop-bpfcc cpudist-bpfcc cpuunclaimed-bpfcc criticalstat-bpfcc dbslower-bpfcc dbstat-bpfcc dcsnoop-bpfcc dcstat-bpfcc deadlock-bpfcc dirtop-bpfcc drsnoop-bpfcc execsnoop-bpfcc exitsnoop-bpfcc ext4dist-bpfcc ext4slower-bpfcc filelife-bpfcc fileslower-bpfcc filetop-bpfcc funccount-bpfcc funcinterval-bpfcc funclatency-bpfcc funcslower-bpfcc gethostlatency-bpfcc hardirqs-bpfcc inject-bpfcc javacalls-bpfcc javaflow-bpfcc javagc-bpfcc javaobjnew-bpfcc javastat-bpfcc javathreads-bpfcc killsnoop-bpfcc klockstat-bpfcc llcstat-bpfcc mdflush-bpfcc memleak-bpfcc mountsnoop-bpfcc mysqld_qslower-bpfcc netqtop-bpfcc nfsdist-bpfcc nfsslower-bpfcc nodegc-bpfcc nodestat-bpfcc offcputime-bpfcc offwaketime-bpfcc oomkill-bpfcc opensnoop-bpfcc perlcalls-bpfcc perlflow-bpfcc perlstat-bpfcc phpcalls-bpfcc phpflow-bpfcc phpstat-bpfcc pidpersec-bpfcc profile-bpfcc pythoncalls-bpfcc pythonflow-bpfcc pythongc-bpfcc pythonstat-bpfcc readahead-bpfcc reset-trace-bpfcc rubycalls-bpfcc rubyflow-bpfcc rubygc-bpfcc rubyobjnew-bpfcc rubystat-bpfcc runqlat-bpfcc runqlen-bpfcc runqslower-bpfcc shmsnoop-bpfcc slabratetop-bpfcc sofdsnoop-bpfcc softirqs-bpfcc solisten-bpfcc sslsniff-bpfcc stackcount-bpfcc statsnoop-bpfcc swapin-bpfcc syncsnoop-bpfcc syscount-bpfcc tclcalls-bpfcc tclflow-bpfcc tclobjnew-bpfcc tclstat-bpfcc tcpaccept-bpfcc tcpconnect-bpfcc tcpconnlat-bpfcc tcpdrop-bpfcc tcplife-bpfcc tcpretrans-bpfcc tcprtt-bpfcc tcpstates-bpfcc tcpsubnet-bpfcc tcpsynbl-bpfcc tcptop-bpfcc tcptracer-bpfcc threadsnoop-bpfcc tplist-bpfcc trace-bpfcc ttysnoop-bpfcc vfscount-bpfcc vfsstat-bpfcc wakeuptime-bpfcc xfsdist-bpfcc xfsslower-bpfcc zfsdist-bpfcc zfsslower-bpfcc
大部分都是python脚本。此处可以有 Gregg 的那张图
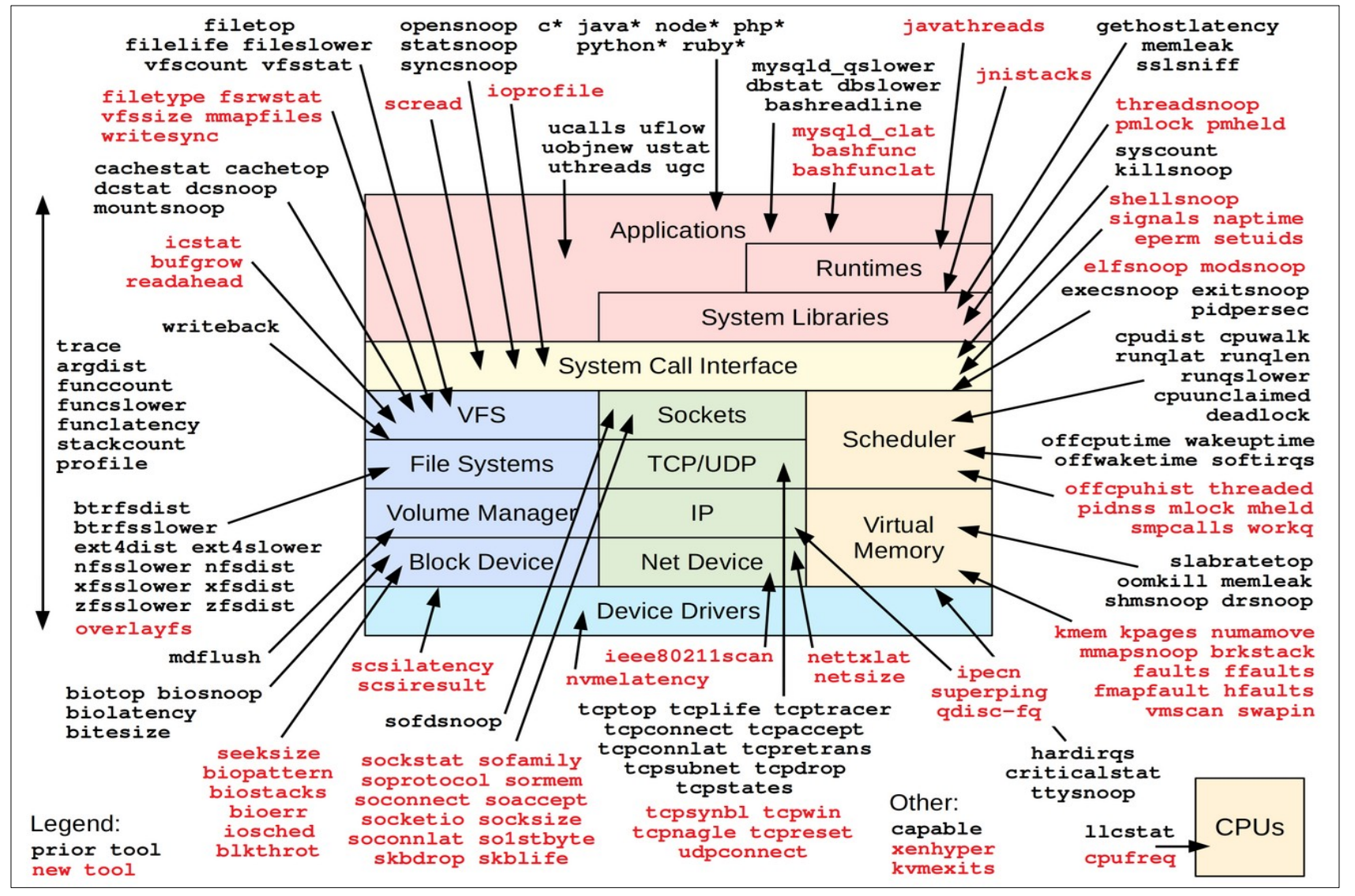
部分示例
execsnoop
execsnoop 会以行输出每个新的进程,用于检查生命周期比较短的进程,这些进程会消耗CPU资源,但不会出现在大多数以周期性采集正在运行的进程快照的监控工具中。
该工具会跟踪exec()系统调用,而不是fork(),因此它能够跟踪大部分新创建的进程,但不是所有的进程(它无法跟踪一个应用启动的工作进程,因为此时没有用到exec())。
这个有点疑问,为什么不是spawn?那是fork
对应使用的是 kprobe和kretprobe

opensnoop
为什么只显示了相对路径?
ext4slower & biolatency & biosnoop
这几个都是块存储相关的,可用于 slow io 探测
kprobe+kretprobe 计算delta时间 到histagram
runqlat
run queue latency
查看run队列等待时间
tcpconnect+tcpaccept+tcpretrans
网络相关
memleak
测内存泄露的
mysqld*
基本上是用 USDT (DTrace)搞的,8.0 已经移除。5.7 有一个宏可以控制开不开 DTrace,翻了一下源码,这东西默认也不开。
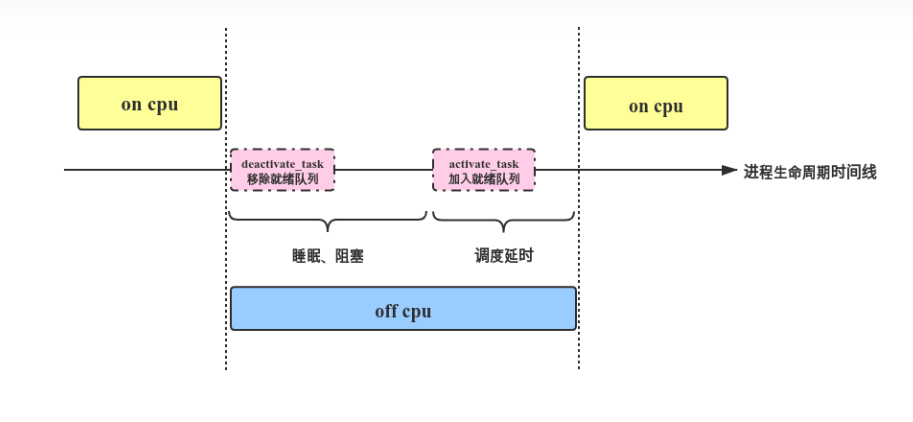
offcputime
off-CPU time: 进程失去cpu使用权时度过的时间
profiling
有点意义不明,觉得不如 bpftrace
funccount
名词
- xdp – eXpress Data Path 网络用的
- kprobe
https://docs.kernel.org/trace/kprobes.html
这个需要再看一下 - uprobe
对任意用户函数插桩
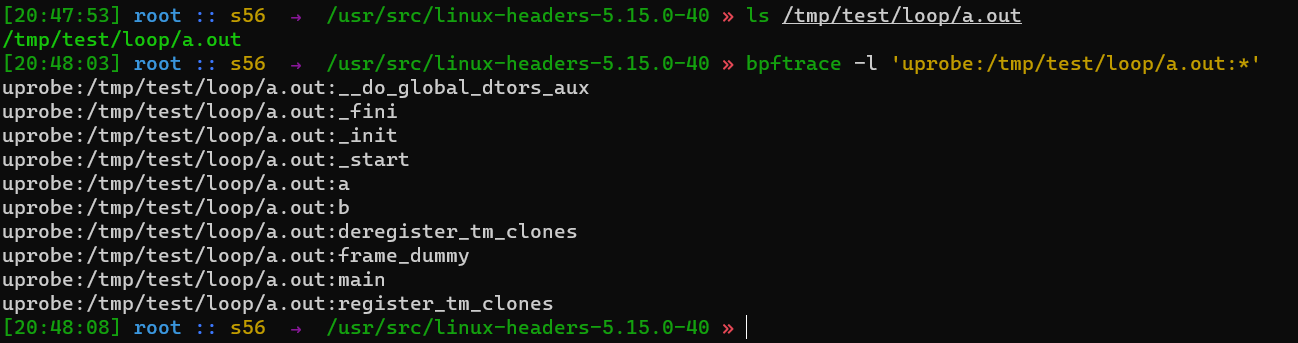
开销问题? - 内核源码树
- nm 命令
看符号表的 - pmc 性能监控计数器 Performance Monitoring Counter
- https://zhuanlan.zhihu.com/p/215125585
- pmu
- pmi Performance Monitoring Interrupt
- 动态插桩和静态插桩
-
- 动态:kprobe内核 uprobe用户
- 静态 需要写到代码里:tracepoints内核 USDT用户
- tasklet
bpftrace
Terminology
|
Term |
Description |
|
BPF |
Berkeley Packet Filter: a kernel technology originally developed for optimizing the processing of packet filters (eg, tcpdump expressions) |
|
eBPF |
Enhanced BPF: a kernel technology that extends BPF so that it can execute more generic programs on any events, such as the bpftrace programs listed below. It makes use of the BPF sandboxed virtual machine environment. Also note that eBPF is often just referred to as BPF. |
|
probe |
An instrumentation point in software or hardware, that generates events that can execute bpftrace programs. |
|
static tracing |
Hard-coded instrumentation points in code. Since these are fixed, they may be provided as part of a stable API, and documented. |
|
dynamic tracing |
Also known as dynamic instrumentation, this is a technology that can instrument any software event, such as function calls and returns, by live modification of instruction text. Target software usually does not need special capabilities to support dynamic tracing, other than a symbol table that bpftrace can read. Since this instruments all software text, it is not considered a stable API, and the target functions may not be documented outside of their source code. |
|
tracepoints |
A Linux kernel technology for providing static tracing. |
|
kprobes |
A Linux kernel technology for providing dynamic tracing of kernel functions. |
|
uprobes |
A Linux kernel technology for providing dynamic tracing of user-level functions. |
|
USDT |
User Statically-Defined Tracing: static tracing points for user-level software. Some applications support USDT. |
|
BPF map |
A BPF memory object, which is used by bpftrace to create many higher-level objects. |
|
BTF |
BPF Type Format: the metadata format which encodes the debug info related to BPF program/map. |
- https://mariadb.org/wp-content/uploads/2020/02/eBPF-and-Dynamic-Tracing-for-MariaDB-DBAs-MariaDB-Day-During-FOSDEM-2020.pdf
- http://mysqlentomologist.blogspot.com/2020/01/using-bpftrace-on-fedora-29-more.html
- 官方文档 & 手册
misc
99Hz? 100Hz?
the value ’99’ and not ‘100’ is to avoid lockstep sampling, which can produce skewed results.
避免锁步采样
锁步采样是指分析样本与应用程序中的循环频率相同的情况.结果是样本经常出现在循环中的相同位置,因此它会认为该操作是最常见的操作,并且可能是瓶颈
这个在ebpf之巅也写了,可以再看一下
libbcc vs libbbpf
bcc-tools vs libbpf-tools
perf 是怎么实现的?
“bpf 程序”?
bpftrace to viz?
bpftrace demangle
一定会启用
pmc vs perf_events
讲的不是一个事
PMC是perf_events的一个源
- https://web.eece.maine.edu/~vweaver/projects/perf_events/faq.html
- https://www.brendangregg.com/perf.html
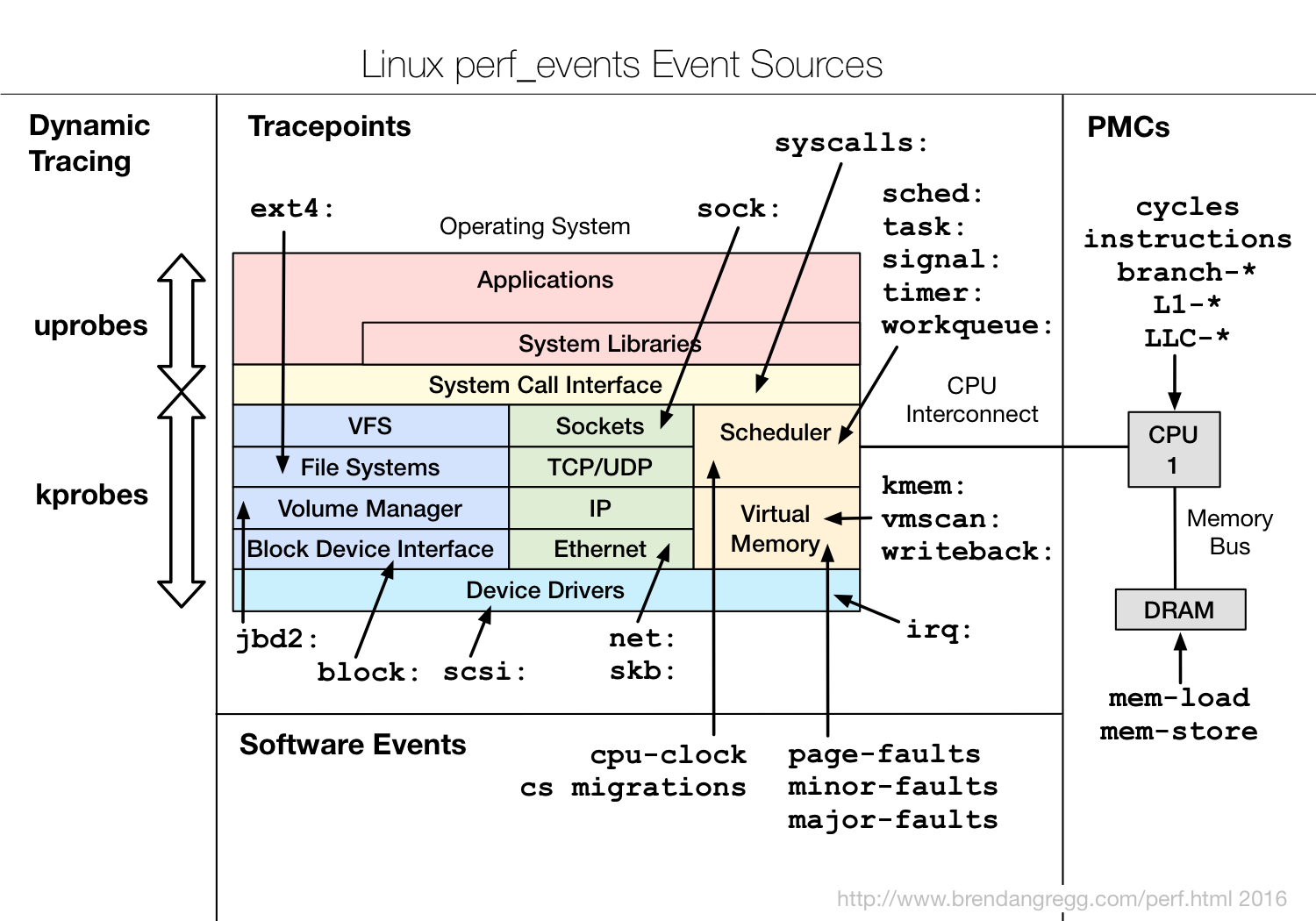
bcc 和 bpftrace 怎么区分栈的(map 的 key)
unwind + hash,需要一个上下文+map
《bpf 之巅》
- p19 3.18 bpf syscall 进入内核
- p40 ebpf 限制
-
- 5.3 支持受限循环
- 栈空间大小 512k
- (5.2 前)指令数量 4096 内
- p42 -fno-omit-frame-pointer 启动 rbp 作为函数帧指针 RDS 默认开启 试一试
不开也能出堆栈 - p60 蹦床函数解释:是因为在执行过程中函数会跳入,然后再跳出这个处理函数
- perf 原理?执行的哪些代码?
- p193 off-cpu 和 on-cpu
- 227-232 profile / offcputime
- 258
-
- 进程所使用的全部物理内存数量成为常驻集大小 (Resident set size,RSS)
- 三种内存页
-
-
- 文件系统页
- 被修改过的文件系统页(脏页)
- 匿名页
-
- 549
-
- ebpf对于函数的分析能力(5点)
- 552 readelf和nm区别 objdump?
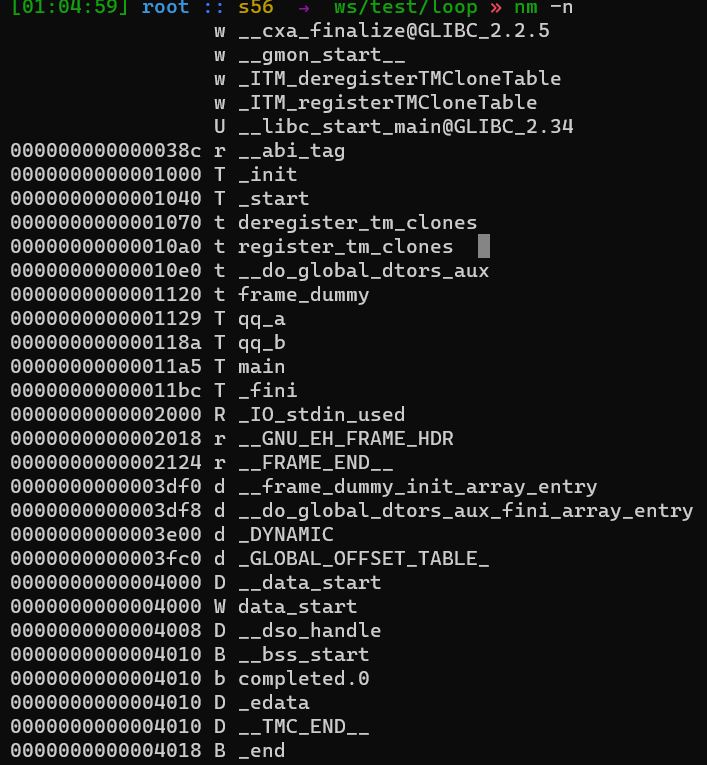
看一下c语言程序内存结构 - 747 Grafana
-
- 按书中描述,还不是开箱即用级的,还需要很多额外工作
- clouflare ebpf prometheus exporter 云原生的用法
- 759 执行操作的成本
《Linux内核观测技术BPF》
32开本,169页,字体超大,79元,脸都不要了
这本书偏向不用库来解释 eBPF,仅使用系统调用,相对底层。
- 58
-
- 内核探针没有稳定的 ABI,(内核探针)可能随内核版本的演进而更改
- 61
-
- (跟踪点)内核保证旧版本上的 tracepoint 将在新版本上存在
- (跟踪点)不会涵盖到内核的所有子系统
传统方式
ring buffer
perf_event_open
![]() 本作品使用基于以下许可授权:Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
本作品使用基于以下许可授权:Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.